![]()
2025/4/18 ものづくりニュース
富士通、マルチモーダルLLM搭載の映像解析型AIエージェントを開発
この記事の内容をまとめると…
- 富士通株式会社が映像解析型AIエージェントを開発
- マルチモーダルLLMによる自己学習技術とコンテキスト記憶技術を搭載
- 評価環境「FieldWorkArena」をカーネギーメロン大学監修で開発
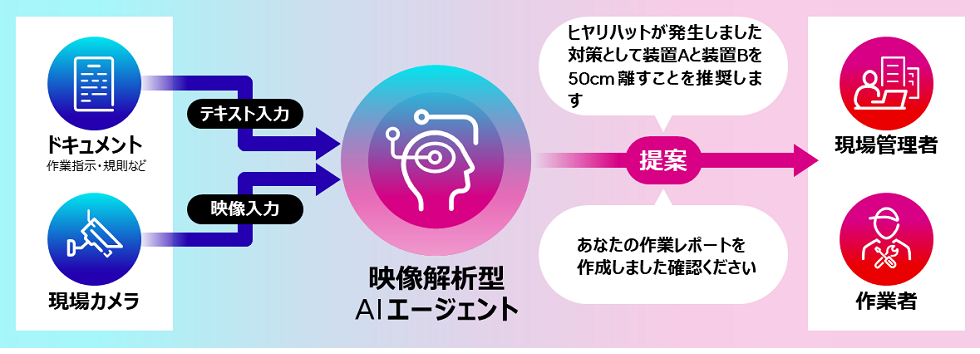
業務に関わる映像とドキュメントを解析し、現場改善を自律的に支援する映像解析型AIエージェントを富士通株式会社が開発した。2025年1月より社内実践を行い、2024年度中にトライアル環境を提供予定である。
映像解析型AIエージェント詳細
富士通株式会社が開発した映像解析型AIエージェントは、製造・物流現場に設置されたカメラ映像を解析し、作業指示や規則などのドキュメント情報と連携することで、作業レポート作成や改善提案を自律的に実行する。マルチモーダル大規模言語モデル(マルチモーダルLLM)を基盤に、2つの技術を搭載している。
1つは、自己学習技術である。ドキュメント情報と映像情報を対応させて学習し、AIが空間的関係性を理解することで、3次元で人と物体の距離を推定できる。これにより、作業状況の生産管理システムへの自動入力や安全管理の支援が可能となる。また、空間理解能力に加え、現場固有の物体認識、人の個別作業の認識など、現場作業支援に必要な様々な能力をAIエージェントに追加できるようになる。
もう1つは、コンテキスト記憶技術である。AIエージェントが重要な情報に注意を集中する「選択的注意」機構を活用し、主題に適合する特徴量のみを抽出し映像コンテキストメモリとして記憶。これにより長時間映像でも高精度に解析できる。2時間以上の映像を含む長時間映像に対する質問回答のベンチマークを行った結果、開発方式は従来のマルチモーダルLLM向けの映像圧縮技術と比較して最小の記憶容量で世界最高の回答精度を達成しました。
関連リンク
![]()